JSON查询语言或方法 JMESPath
什么是JMESPath
JMESPath 是查询 JSON 数据的查询语言. 可以快速解析复杂的JSON数据.
通过定义jmespath, 可以将数据提取, 数据筛选, 数据格式转换 动作只需一步即可完成, 大大加快对于复杂的JSON数据的处理速度.
为了展示它的强大之处, 看下面这个例子, 输入如下 jmespath, 对目标数据的locations字段进行处理.
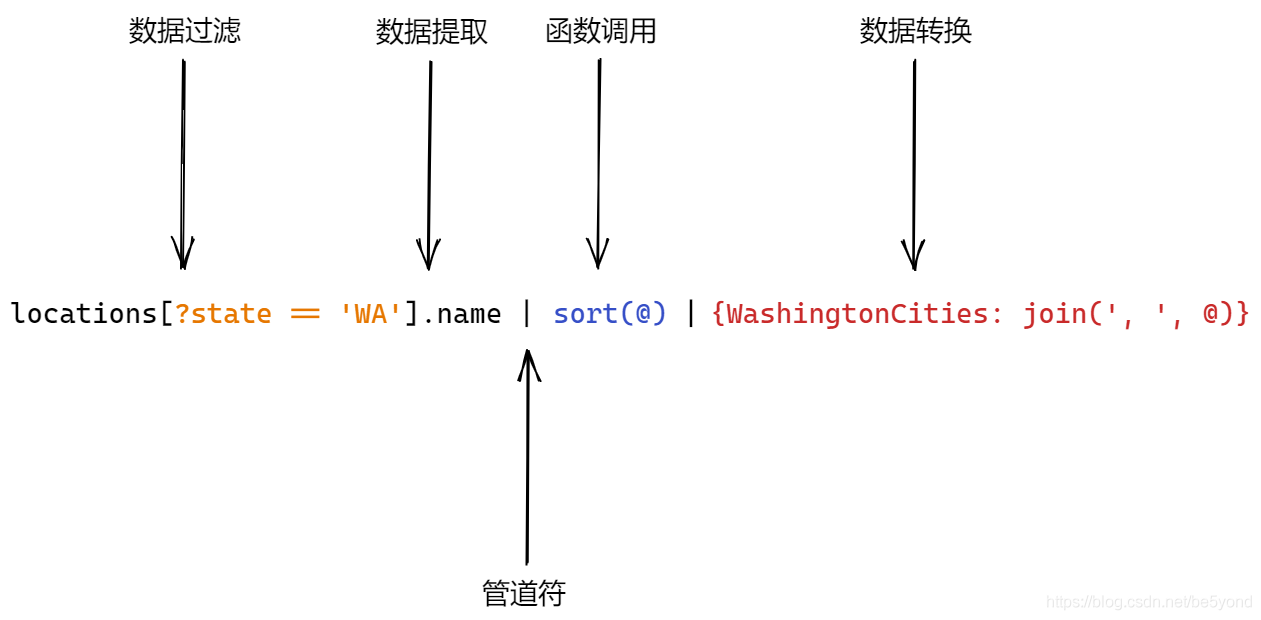
- 找到locations字段下的数据, 过滤state == ‘WA’ 的数据, 提取name字段
- 将结果数据传递给sort函数进行排序
- 将排序后的数据, 传递给join函数, 转换格式, 填到新的字典中, 返回新的数据.
各步骤数据转化如下图:

等价的python代码实现
In [1]: data = {
...: "locations": [
...: {"name": "Seattle", "state": "WA"},
...: {"name": "New York", "state": "NY"},
...: {"name": "Bellevue", "state": "WA"},
...: {"name": "Olympia", "state": "WA"}
...: ]
...: }
In [2]: names = [loc['name'] for loc in data['locations'] if loc['state'] == 'WA']
In [3]: cities = ', '.join(sorted(names))
In [4]: {'WashingtonCities': cities}
Out[4]: {'WashingtonCities': 'Bellevue, Olympia, Seattle'}下面 我们详细介绍JMESPath 都有哪些功能.
1. 数据提取
1.1 基本表达式 .
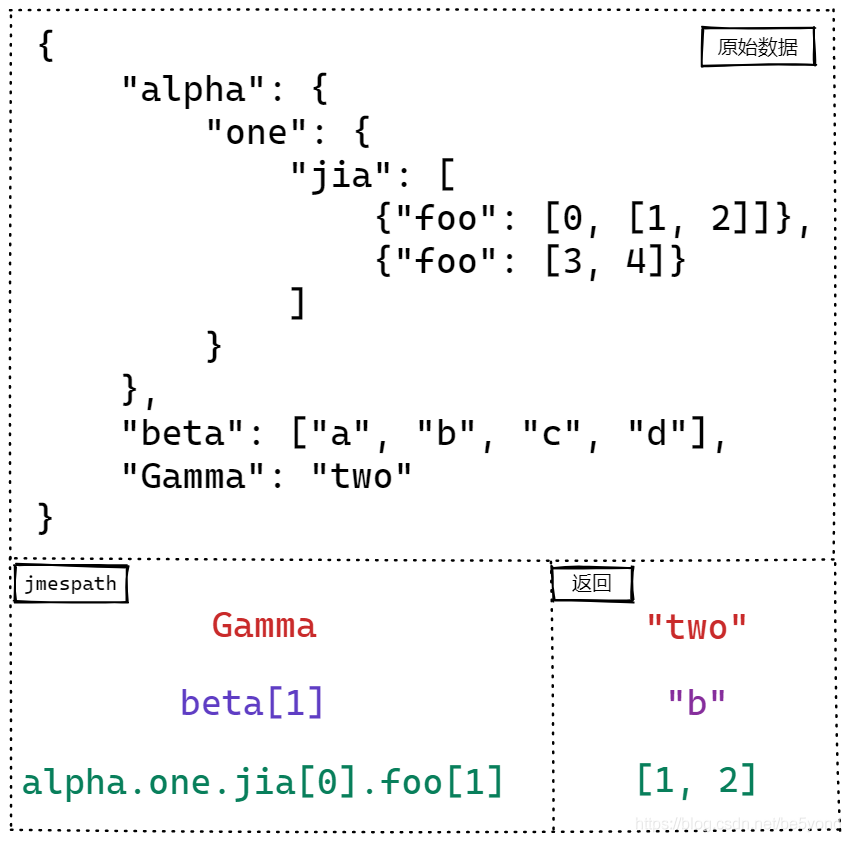
JMESPath 使用 ‘.’ 来获取JSON数据中下一层级别的数据. 使用[index]坐标来获取数组中对应位置的数据.
在代码中使用, 调用jmespath的search方法,
search(jmespath: str, data: JSON) -> value: Union[str, list, dict]- jmespath: JMESPath的查询语句
- data: 目标JSON 数据
代码示例:
In [1]: from jmespath import search
In [2]: data = {
...: "alpha": {
...: "one": {
...: "jia": [
...: {"foo": [0, [1, 2]]},
...: {"foo": [3, 4]}
...: ]
...: }
...: },
...: "beta": ["a", "b", "c", "d"],
...: "Gamma": "two"
...: }
In [3]: search('Gamma', data)
Out[3]: 'two'
# 没有的数据 返回None
In [4]: search('Beta[1]', data)
In [5]: search('beta[1]', data)
Out[5]: 'b'
In [6]: search('alpha.one.jia[0].foo[1]', data)
Out[6]: [1, 2]1.2 切片
对于数组类型的数据, 支持向python一样格式的切片方式[start:end:step].
| jmespath | 返回 |
|---|---|
| 原始数据 | [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] |
| [*] | [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] |
| [] | [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] |
| [::] | [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] |
| [5:10] | [5, 6, 7, 8, 9] |
| [::-1] | [9, 8, 7, 6, 5, 4, 3, 2, 1, 0] |
| [8:1:-2] | [8, 6, 4, 2] |
1.3 通配符 *
jmespath 中支持将* 作为通配符,匹配所有元素.

代码示例:
In [1]: from jmespath import search
In [2]: data = {
...: "alpha": {
...: "one": "jia",
...: "two": "bai"
...: },
...: "beta": {
...: "one": "ping",
...: "two": "pang"
...: },
...: "Gamma": {"two": "Gado"}
...: }
In [3]: search('alpha.*', data)
Out[3]: ['jia', 'bai']
In [4]: search('*.two', data)
Out[4]: ['bai', 'pang', 'Gado']1.4 管道符 |
jmespath 中的管道符作用和shell命令中的作用一样, 将前一个表达式返回的结果作为后一个表达式的输入进行计算.
In [5]: search('*.two[0]', data)
Out[5]: []
In [6]: search('*.two | [0]', data)
Out[6]: 'bai'在上面示例中, 我们想获取第一个two字段对应的value, 不能直接使用two[0], 因为它的意思是获取two的第一个元素, two字段的数据不是列表,所以返回的是null. 使用管道符将*.two,表达式的返回 [‘bai’, ‘pang’, ‘Gado’] 传给后面的表达式 [0] 从而获取到第一个元素 ‘bai’
1.5 多字段提取 [] {}
我们已经了解了 JMESPath 表达式基本使用,通过 . 和[index]从 JSON 数据中抽取我们需要的元素. 通过使用 多选列表[] 和多选hash {}, 可以创建 原始JSON数据不存在的 元素。
In [1]: from jmespath import search
In [2]: data = {
...: "people": [
...: {"name": "a", "state": {"name": "up"} },
...: {"name": "b", "state": {"name": "down"} },
...: {"name": "c", "state": {"name": "up"} }
...: ]
...: }
In [3]: search('people[].[name, state.name]', data)
Out[3]: [['a', 'up'], ['b', 'down'], ['c', 'up']]在上面的表达式中,[name, state.name]部分是一个多选列表。它要创建一个包含两个元素的列表,第一个元素是name表达式的结果,第二个元素是state.name的结果。
In [4]: search('people[].{new_name: name, state_name: state.name}', data)
Out[4]:
[{'new_name': 'a', 'state_name': 'up'},
{'new_name': 'b', 'state_name': 'down'},
{'new_name': 'c', 'state_name': 'up'}]在上面的表达式中,{new_name: name, state_name: state.name}部分是一个多选字典。它要创建一个包含两个元素的字典,第一个元素key是’new_name’, value是name表达式的结果,第二个元素key是’state_name’, value是state.name的结果。
利用这个特性, jmespath可以轻松处理例如替换掉JSON数据的key的操作.
总结
本文介绍了 JMESPath的用途, 和基本的使用方法, 包括如何使用 .和坐标定位json中的数据, 使用管道符进行数据传递, 使用[] {} 进行多个字段的提取和映射.
使用JMESPath的优势,
- 可以避免KeyError和IndexError, 使代码更加健壮
- 将解析json数据的过程可以抽象成一条jmespath数据, 非常适合一些需要参数化的场景.
来源:https://blog.csdn.net/be5yond/article/details/118976017
其他参考: