调整数据库表结构,搞定 WordPress 数据库查询缓慢问题
同事的基于 WordPress 搭建的网站,因为数据越来越多,变得慢,我从 PHP slow log 里面看出是 WordPress 有些查询总是很慢,即使已经安装了页面缓存插件,但是由于页面众多,命中率不高,所以加速效果也不明显,而且由于界面经常改版,页面缓存需要清空重新生成,进一步降低了缓存的效果。反正就是不流畅,有点慢。
看了下服务器配置虽然不高,但是也不至于打开一个一面要 4 秒钟吧,而且 CPU 占用率奇高,虽然说升级硬件可以缓解,但根源还是程序效率的问题,所以不妨先趁性能出现问题的情况下,优化程序,解决程序的性能问题后,再升级服务器硬件,这样效果才持久。
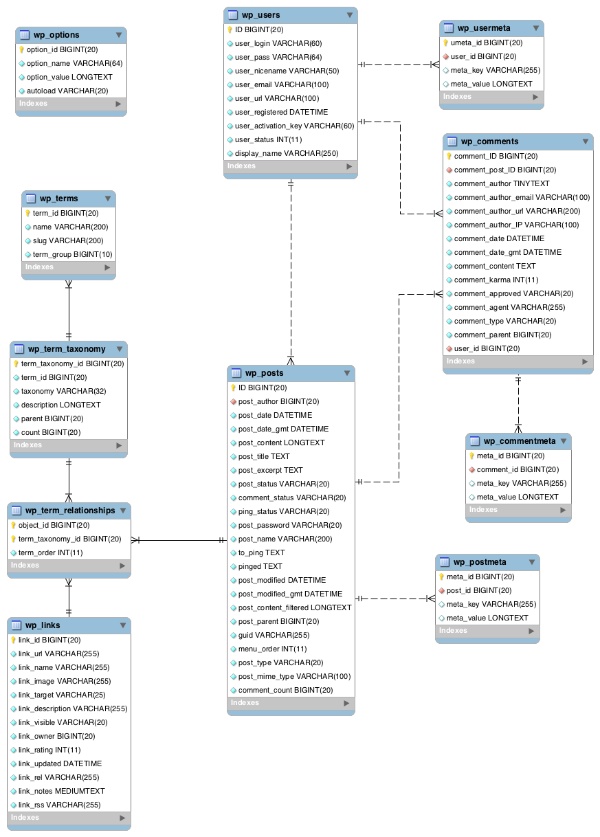
于是乎打算从表结构上作些优化。主要影响性能的,是两张表:wp_postmeta、wp_term_relationships、wp_posts
先看一下最终结果:
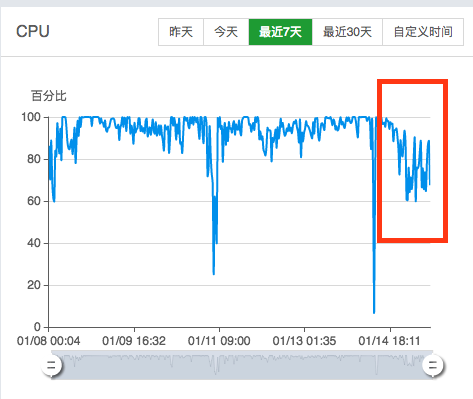
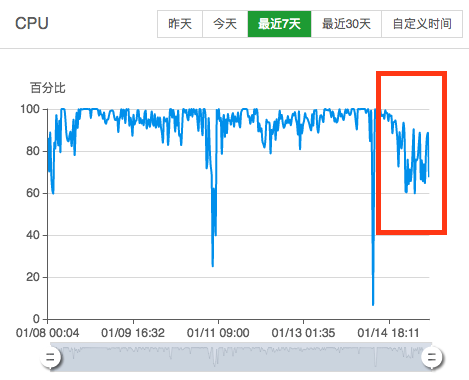
可以看到 CPU 明显下降了不少(那两个剧烈波动的折线请忽略,跟本文无关)。
优化过程
先介绍一下本次优化涉及到的数据库表结构:
业务和表的关系
|
内容类型
|
数据表
|
|
文章
|
wp_posts
|
|
页面
|
wp_posts
|
|
自定义文章类型
|
wp_posts
|
|
附件
|
wp_posts
|
|
导航菜单
|
wp_posts
|
|
文章元数据
|
wp_post_meta
|
|
分类目录
|
wp_terms
|
|
标签
|
wp_terms
|
|
自定义分类法
|
wp_term_taxonomy
|
表之间的关系
|
数据表
|
存储的数据
|
关联到
|
|
wp_posts
|
文章、页面、附件、版本、导航菜单项目
|
wp_postmeta (通过post_id关联)
|
|
wp_postmeta
|
每个文章的元数据
|
wp_posts (通过 post_id关联)
|
|
wp_term_relationships
|
文章和自定义分类法之间的关系
|
wp_posts (通过 post_id 关联)
wp_term_taxonomy (通过term_taxonomy_id 关联)
|
|
wp_term_taxonomy
|
自定义分类法(包括默认的分类目录和标签)
|
wp_term_relationships(通过 term_taxonomy_id关联)
|
|
wp_terms
|
关联到分类法中的分类目录,标签和自定义分类项目
|
wp_term_taxonomy (通过term_id 关联)
|
wp_postmeta 是查询最慢的一张表,它存放文章/页面/自定义内容(wp_posts)的元数据信息,所谓元数据,也包括如文章查看数、封面图片,还有你自定义的字段。
按理说,一篇文章(wp_posts),对应 wp_postmeta 一行记录,为啥会慢呢?原因是,WordPress 把 wp_postmeta 设计成了一张纵表,而且没有恰当的索引。
关于横表和纵表,横表是我们做项目最常用的,不清楚这个概念的朋友,看下面的的小实验就明白了:
普通横表 STUDENT_SCORE 有语文成绩、英语成绩等7个KPI指标,三个学生的三条记录:
SQL> SELECT * FROM STUDENT_SCORE;
Id CHINESE_SCORE ENGLISH_SCORE MATH_SOCRE PHYSICAL_SCORE SPORTS_SCORE CHEMICAL_SCORE BIOLOGICAL_SCORE
<span style="font-size: 13.3333px; letter-spacing: normal; orphans: 2; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); color: rgb(51, 51, 51); font-family: "PingFang SC", "Microsoft YaHei", "Helvetica Neue", Helvetica, Arial, sans-serif; font-variant-caps: normal; font-variant-ligatures: normal;"–<——— ————- ————- ———- ————– ———— ————– —————-
10001 87.4 63 92 86 75 85 89
10002 91 89 98 62 76 82 73
10006 74 63 57 42 76 59 67
对应于纵表/竖表,这三个学生的7个KPI指标需要21条记录才能描述清楚:
SQL> SELECT * FROM STUDENT_SCORE;
Id FieldName Value
<span style="font-size: 13.3333px; letter-spacing: normal; orphans: 2; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); color: rgb(51, 51, 51); font-family: "PingFang SC", "Microsoft YaHei", "Helvetica Neue", Helvetica, Arial, sans-serif; font-variant-caps: normal; font-variant-ligatures: normal;"–<——— ——————— ———-
10001 CHINESE_SCORE 87.4
10001 ENGLISH_SCORE 63
10001 MATH_SOCRE 92
10001 PHYSICAL_SCORE 86
10001 SPORTS_SCORE 75
10001 CHEMICAL_SCORE 85
10001 BIOLOGICAL_SCORE 89
10002 CHINESE_SCORE 91
10002 ENGLISH_SCORE 89
10002 MATH_SOCRE 98
10002 PHYSICAL_SCORE 62
10002 SPORTS_SCORE 76
10002 CHEMICAL_SCORE 82
10002 BIOLOGICAL_SCORE 73
10006 CHINESE_SCORE 74
10006 ENGLISH_SCORE 63
10006 MATH_SOCRE 57
10006 PHYSICAL_SCORE 42
10006 SPORTS_SCORE 76
10006 CHEMICAL_SCORE 59
10006 BIOLOGICAL_SCORE 67
所以我们从这个小实验中可以看到,横表转成纵表/竖表,对应的记录会翻倍增长,这对应于数据量大的表或宽表,都是一件不好的消息。很多时候,数据量上去了,性能问题就出来了。
分析得到 WordPress 从来是不会根据 meta_id 去查 postmeta 表的,都是根据 post_id 去查 post 的单个 meta 信息或者所有 meta key 和 value,所以原本的主键 meta_id 仍然保持自增(因为 的,它就仅仅是一个自增 ID)
提升性能的办法是把 post_id 和 meta_key 改为主键,然后根据 post_id 做分区表,这样,这样有两个好处,一是查询时,可以根据 post_id 去读区分区表的数据了,不用再全表查找了,另外是这俩字段组成唯一约束和索引了,查询速度自然会加快,而原本的主键 meta_id 仍然保持自增,不会影响到原本的业务逻辑。
WordPress 默认没有为 wp_postmeta 的表没有设定 post_id 和 meta_key 的唯一约束,也就是说,是存在一个 post 再 postmeta 表有多个同样的的 meta key 和 value 的情况的,我验证了一下:
SELECT *FROM
wp_postmeta pm
WHERE
meta_id NOT IN (
SELECT max(meta_id) FROM wp_postmeta pm2 where pm2.post_id=pm.post_id and pm2.meta_key=pm.meta_key
)
SELECT distinct meta_key From wp_postmeta Group By post_id,meta_key Having Count(*)>1
返回内容大致如下:
/*
'_wp_old_slug'
'_thumbnail_id'
'_edit_lock'
*/
确实是这样,但是看了下都是 WordPress 运行过程中产生的垃圾数据,是可以无副作用删除的,那么此路是可行的。
好,那么,先先清理下垃圾数据:
DELETE FROM wp_postmeta WHERE meta_key = '_edit_lock';
DELETE FROM wp_postmeta WHERE meta_key = '_edit_last';
DELETE FROM wp_postmeta WHERE meta_key = '_revision-control';
DELETE FROM wp_postmeta WHERE post_id NOT IN (SELECT post_id FROM wp_posts);
DELETE FROM wp_postmeta WHERE meta_key = '_wp_old_slug';
DELETE FROM wp_postmeta WHERE meta_key = '_revision-control';
DELETE FROM wp_postmeta WHERE meta_value = '{{unknown}}’;
然后,删除掉重复的 meta key 和 value 记录,仅保留最新的一个
DELETEFROM
wp_postmeta
WHERE
meta_id IN (
select * from (
select meta_id
FROM
wp_postmeta pm
WHERE
meta_id NOT IN (
SELECT max(meta_id) FROM wp_postmeta pm2 where pm2.post_id=pm.post_id and pm2.meta_key=pm.meta_key
)
) as g1
)
这里存在一个问题,就是 WordPress 在开启了文章的版本控制情况下,是存在插入重复 post 和 meta key 的情况的,数据库改成唯一约束后会报错,或者其它插件会这么做,解决办法是,WordPress 里面 Hook 一下 add metadata 函数,insert 前先 check 是否已经 exists,另外就是数据库里面加个 Trigger 做判断,如果已存在,就更新。
数据清理完毕,那么可以开始建立分区表了
必须先 ADD UNIQUE(`meta_id`),才能 DROP meta_id 的 PRIMARY KEY。
ALTER TABLE `wp_postmeta`
ADD UNIQUE INDEX `UNQ_meta_id` (`meta_id` ASC);
ALTER TABLE `wp_postmeta`
DROP PRIMARY KEY (`meta_id`);
再 DROP 掉 meta_id 的 UNIQUE,这是因为后面分区,要求 RANGE 分区列的UNIQUE INDEX 必须包含所有 primary key ,即任意 UNIQUE INDEX 都要包含 post_id,meta_key 分区函数列,否则分区函数是无法创建,会报错误:Error Code: 1503. A UNIQUE INDEX must include all columns in the table's partitioning function。
ALTER TABLE `wp_postmeta`
DROP UNIQUE INDEX `UNQ_meta_id` (`meta_id` ASC);
ALTER TABLE `wp_postmeta`
ADD PRIMARY KEY (`post_id`, `meta_key`);
ALTER TABLE `wp_postmeta`
CHANGE COLUMN `meta_key` `meta_key` VARCHAR(255) NOT NULL ,
CHANGE COLUMN `post_id` `post_id` BIGINT(20) UNSIGNED NOT NULL ;
ALTER TABLE `wp_postmeta`
ADD UNIQUE INDEX `UNQ_post_id_meta_key` (`post_id` ASC, `meta_key` ASC),/* 这句可以加可以不加,因为已经是 PRIMARY KEY */
ADD UNIQUE INDEX `UNQ_meta_id_post_id_meta_key` (`meta_id` ASC, `post_id` ASC, `meta_key` ASC);
好了,先看下 post 表 id 的分布,我的是从 id 从 5万到11万,先给 posts 表分好区:
SELECT id FROM wp_posts order by id asc;
ALTER TABLE wp_posts PARTITION BY RANGE(id) (
PARTITION p0 VALUES LESS THAN (60000),
PARTITION p1 VALUES LESS THAN (70000),
PARTITION p2 VALUES LESS THAN (80000),
PARTITION p3 VALUES LESS THAN (90000),
PARTITION p4 VALUES LESS THAN (100000),
PARTITION p5 VALUES LESS THAN (110000),
PARTITION p6 VALUES LESS THAN MAXVALUE
);
wp_postmeta 表,也如法炮制,这样再查询 post 的 meta,不但不用全表扫描,只用扫分区内的数据了,而且还可以走索引 :
ALTER TABLE wp_postmeta PARTITION BY RANGE COLUMNS(post_id,meta_key) (
PARTITION p0 VALUES LESS THAN (60000,MAXVALUE),
PARTITION p1 VALUES LESS THAN (70000,MAXVALUE),
PARTITION p2 VALUES LESS THAN (80000,MAXVALUE),
PARTITION p3 VALUES LESS THAN (90000,MAXVALUE),
PARTITION p4 VALUES LESS THAN (100000,MAXVALUE),
PARTITION p5 VALUES LESS THAN (110000,MAXVALUE),
PARTITION p6 VALUES LESS THAN (MAXVALUE,MAXVALUE)
);
另外, 这个表的查询也比较耗时,把 object_id,term_taxonomy_id 改为主键后,也分下区:
ALTER TABLE wp_term_relationships PARTITION BY RANGE COLUMNS(object_id,term_taxonomy_id) (
PARTITION p0 VALUES LESS THAN (60000,MAXVALUE),
PARTITION p1 VALUES LESS THAN (70000,MAXVALUE),
PARTITION p2 VALUES LESS THAN (80000,MAXVALUE),
PARTITION p3 VALUES LESS THAN (90000,MAXVALUE),
PARTITION p4 VALUES LESS THAN (100000,MAXVALUE),
PARTITION p5 VALUES LESS THAN (110000,MAXVALUE),
PARTITION p6 VALUES LESS THAN (MAXVALUE,MAXVALUE)
);
最后,顺便根据 MySQL 的统计信息,对 MySQL 的性能参数做了适当的调整:
性能调整对应的参数表格:
增大了 sort_buffer_size ,使得原本【创建临时表到磁盘】有 51%,增加 tmp_table_size 调整后降低到 29.36% 。
分区后,原本未缓存的页面打开要 4s-5s,现在 2-3s 就可以打开啦。观察一段时间再升级下服务器。
CPU 的使用率也下降了不少(那两个剧烈波动的折线请忽略,那个是之前别的进程hang了,跟本次无关)。
然后找了个网站速度测试工具,输入网址测试一下:
另外我本来是熟 SQL Server 数据库优化的,MySQL 的数据库优化其实一直都是以过去 SQL Server 优化经验为指导的,有些地方可能存在盲区和不足,如果有还请指出,谢谢!